

Creating a Magic Mirror
how I created a magic mirror with voice interaction
Let's start a new project!
It's been a while since my last blog post. This is mainly because I invest a lot of time in work and the advancement of my game. But probably also because I'm working on a new project that I'm excited about. I would like to introduce that project in this blog article.
You've probably heard of a "magic mirror" or "smart mirror" before, haven't you?
For those unfamiliar with the term, here is a brief explanation:
A smart mirror, also known as a magic mirror, displays the time, weather, calendar, news, and other custom things. The magic is created by placing a transparent mirror over a screen such as a tablet, monitor, or TV. The technology is mostly driven by a Raspberry Pi.
My idea is to run a local web server on a Raspberry Pi. So I can create the entire application in HTML / CSS / JavaScript and PHP.
I plan to add the following features:
- Display the current date and time
- Show when a train is arriving
- Show how the weather is
- Show my Google calendar entries
- View news feeds
Show current Bitcoin price(nope, not that shit)
Some of you would ask me now, why I'm not using existing open source solutions.
That would be boring, no? I want to build and code a magic mirror completely myself for my needs :)

What did I buy to build a magic mirror?
- 1x Raspberry Pi 4 (Set)
- 1x Display (LM290WW2 SS A1)
- 1x Spy mirror (Mirropane CHROME SPY 4 mm)
- 1x USB Audio Stereo Adapter External Sound Card
- 1x Microphone
- 1x Speaker
The most important thing is that a smart mirror consists of a semi-transparent mirror glass (also called spy mirror or one-way mirror) through which light can pass from one side to a certain extent. The light from the screen behind is clearly visible on the front. In this way, the display can show information through the mirror from behind that can be seen by a user standing in front of the mirror.
All black areas on the display and dark areas outside the display are perceived as a normal mirror on the front of the smart mirror.

I ordered test glasses to see which one would fit best. In the end I decided on a semi-transparent mirror glass, 4 mm with a transmission value of 8%.
When choosing the display, I paid attention to a correspondingly high brightness value (min. 250 cd/m²). The size of the display is 2560 x 1080 Pixel (21:9). The mirror glass has to be cut to the dimensions of the display.



Since I also wanted a case and heat sink as additional protection, I opted for a complete Raspberry Pi 4 set. The hardware is complete. Let's start with the application!
Speech Recognition
I want to build a mirror which is interacting with my voice. When I'm saying something, the application should do or show me something. I googled a lot about which technology I should use to realize a solid speech recognition. I found several solutions like: Amazon Alexa or Google Assistant integrations, Voice control based on Sphinx or Annyang.
But wait.. wasn't there an experimental native feature in our browser called Web Speech API?
The Web Speech API enables you to incorporate voice data into web apps.
The API has two parts: SpeechSynthesis (Text-to-Speech), and SpeechRecognition (Asynchronous Speech Recognition.)
MDN Web Docs | W3C Specifiaction (Draft)
That's perfect. It uses Google's servers to perform the conversion. So, using the API sends an audio recording to a Google Server to perform the transcription. The fact that I am using a Chromium based browser on my system guarantees that I have browser compatibility support. The only difference between Chrome and Chromium seems that Chromium does not have Google voices and therefore will not work on machines without voices installed. I read that some chromium builds need the flag --enable-speech-dispatcher, too but I have to test it on my Raspberry.
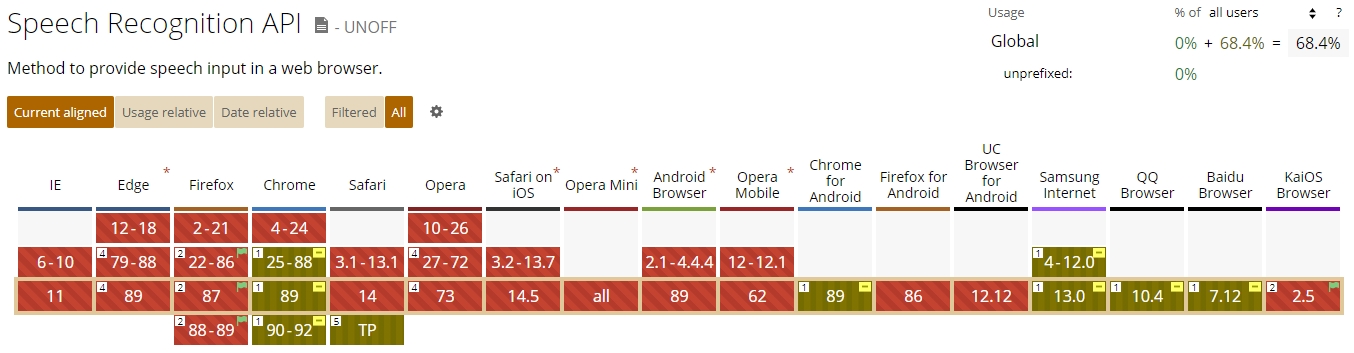
In order for the mirror to be able to communicate with me, voice activation must always be on, so that speech can be recognized at all times.
But that's a problem. If I'm talking with someone in the same room, I don't want the mirror to react.
Amazon is solving this problem by activating the speech recognicing when saying the name "Alexa". I don't want to do it this way.
So how can I solve this Problem? I have a simple trick in mind.
Since the microphone activation is always on, I can convert the incoming audio signal into a audio waveform by using the raw audio stream. A waveform is basicly a audio visualisation that represents the audio signal. It shows the changes in amplitude over a certain amount of time. The amplitude of the signal is measured on the y-axis, while time is measured on the x-axis.
The waveform show us a visual idea of what has been incoming. If the waveform is very low and not pronounced, the recording was very soft. If the waveform almost fills the entire y-axis, the audio have been very load and someone stays in front of the mirror.
What does that mean in detail? Have a look at my concept:
------------------------------------------------------------------------
^
Voice detection area
█ Trigger Web Speech API
█ v
----------█-----------------------------█-------------------------------
█ █ █ ^
█ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ signal/speech
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ |
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ v
--------█-█-█-█-█-█-█-█-█-█-█-█-----█-█-█-█-█-█-█---█-█-█-█---█---------
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ background
█ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ noise
------------------------------------------------------------------------
^ ^ ^ ^ ^ ^ ^ ^ ^ ^
| | | | | | | | | |
| | | Voice detected | signal | signal | |
| | onsoundstart silence silence | |
| | | |
| onaudiostart onaudioend |
onstart onend
This could be false positive in some cases (loud speaking, loud music etc.) but should be very rare if the sensitivity is configured good. Let's try that and create a canvas to visualize the audio stream.
Have a look at my following demo. I coded that the audio wave is changing it's color when the Web Speech API is fired. Don't get confused, the following display is not the mirror. It's my notebook for testing.

By doing this I get a visual interaction when the voice detection is activated. The next part of this series of articles will mainly focus on creating the interface and how it's interacting with this technology. Keep checking my blog, it will be worth it.
Thank you for reading!
